
2Fortgeschrittene String-Verarbeitung 
»Vieles hätte ich verstanden, wenn man es mir nicht erklärt hätte.«
– Stanislaw Jerzy Lec (1909–1966)
2.1Erweitere Zeicheneigenschaften
2.1.1isXXX(….)-Methoden
Die Klasse java.lang.Character steht im Fokus aller Zeichenoperationen, und von den knapp 90 Methoden sind fast die Hälfte Zugehörigkeitsmethoden wie isLetter(char), isWhitespace(char), die also prüfen, ob ein Zeichen in eine gewisse Klasse fällt. Zu den eher exotischen zählen:
implements Serializable, Comparable<Character>
static boolean isJavaIdentifierStart(char ch)
Prüft, ob es ein Java-Buchstabe ist, mit dem Bezeichner beginnen dürfen.static boolean isJavaIdentifierPart(char ch)
Prüft, ob es ein Java-Buchstabe ist oder eine Ziffer, der bzw. die in der Mitte eines Bezeichners vorkommen darf.static boolean isTitleCase(char ch)
Es gibt einige wenige Zeichen, die als ein Zeichen zählen, aber so aussehen wie zwei getrennt geschriebene Zeichen. Dies kommt etwa im Spanischen vor, wo »lj« (\u01C9) bzw. »LJ« (\u01C7) für einen einzigen Buchstaben stehen. Die Methode isTitleCase(char) testet, ob es sich um so ein besonderes Zeichen handelt.
Unicode-Surrogates
Dazu kommen noch eine ganze Reihe isXXX()-Methoden, die sich des Sonderfalls annehmen, dass ein Zeichen über den Wertebereich eines Java-char hinausgeht und als so genanntes Surrogate ausgedrückt wird. Musikalische Symbole etwa liegen im Bereich von U+1D100 bis U+1D1FF.[ 19 ](http://www.fileformat.info/info/unicode/block/musical_symbols/images.htm) Das spezielle Unicode-Zeichen 'MUSICAL SYMBOL HALF NOTE' (U+1D15E) wird in Java als Paar von zwei char-Zeichen "\uD834\uDD5E"[ 20 ](http://www.fileformat.info/info/unicode/char/1d15e/index.htm) geschrieben. Das Paar zeigt schön das High-Surrogate (geht von \uD800 bis \uDBFF) und das Low-Surrogate (von \uDC00 bis \uDFFF). Kein einzelnes Zeichen liegt im Bereich von \uD800 bis \uDFFF, um Mehrdeutigkeiten auszuschließen.
2.1.2Unicode-Blöcke
Unicode-Zeichen gehören immer Blöcken an, und bei denen ist teilweise etwas Platz, um nachrückende Zeichen noch aufnehmen zu können. Beim lateinischen Alphabet ist das nicht so wichtig, wohl aber bei mathematischen Sonderzeichen oder anderen Symbolen.
Die Klasse Character deklariert eine öffentliche statische finale Klasse UnicodeBlock mit einer Vielzahl von Unicode-Blöcken, die als öffentliche statische Variablen in UnicodeBlock deklariert sind und selbst vom Typ UnicodeBlock sind. Character.UnicodeBlock.BASIC_LATIN ergibt zum Beispiel so einen Block, allerdings ist der Typ nicht so ausdrucksstark, nur der Name kommt bei einem toString() dabei heraus, aber nicht etwa, in welchem Bereich die Zeichen liegen. Auch fehlt die Möglichkeit, alle Zeichen aufzuzählen oder zu testen, ob ein Zeichen im Block liegt. Was jedoch der Typ UnicodeBlock bietet, sind zwei statische Methoden of(int) und of(char), die als Fabrikfunktionen einen UnicodeBlock für ein gewisses Zeichen geben. Der Ist-ein-Element-von‐Test lässt sich also damit indirekt realisieren. Die Namen der Blöcke definiert der Unicode-Standard.[ 21 ](http://www.unicode.org/Public/UNIDATA/Blocks.txt)
[zB]Beispiel
Gib die Namen der Unicode-Blöcke für einige Zeichen aus:
System.out.println( basicLatin );
System.out.println( Character.UnicodeBlock.of( 'ß' ) );
System.out.println( Character.UnicodeBlock.of( '\u263A' ) );
System.out.println( Character.UnicodeBlock.of( '\u20ac' ) );
System.out.println( Character.UnicodeBlock.of( 0x1D15E ) );
Das liefert BASIC_LATIN LATIN_1_SUPPLEMENT MISCELLANEOUS_SYMBOLS CURRENCY_SYMBOLS MUSICAL_SYMBOLS.
Das Wissen um den Bereich ist immer dann hilfreich, wenn ein unbekannter Text zugeordnet werden soll, denn auf diese Weise lässt sich erahnen, ob der Text zum Beispiel auf lateinischen Buchstaben basiert, ob er arabisch, chinesisch oder japanisch (Kanji/Kana) ist.
2.1.3Unicode-Skripte
Neben den Unicode-Blöcken gibt es noch ein anderes Konzept, das vielleicht noch wichtiger ist als die Blöcke selbst: Unicode-Skripte. Darunter ist eine Gruppe von Zeichen für eine Sprache (in der Regel) zu verstehen.[ 22 ](Siehe auch http://www.unicode.org/reports/tr24/.) Um den Unterschied zu Blöcken noch einmal zusammenzufassen:
Ein Unicode-Block ist ein einfacher Von-bis-Bereich, und Stellen können für die spätere Belegung leer sein.
Ein Unicode-Skript enthält keine freien Positionen.
Zeichen eines Unicode-Skripts können aus verschiedenen Unicode-Blöcken stammen.
Zeichen aus einem Block können in verschiedenen Unicode-Skripten auftauchen.
Für Skripte bietet Java in der Klasse Character einen öffentlichen, statischen, inneren Aufzählungstyp Character.UnicodeScript. Es besteht aus einer Reihe von Konstanten, wobei die Namen nach ISO 15924[ 23 ](http://unicode.org/iso15924/iso15924-codes.html) gewählt sind. Auch gibt es eine of(int)-Methode, um das Skript für ein Zeichen zu erfragen, und ein UnicodeScript-Objekt kann über forName(String) mit einem Namen aufgebaut werden.
Auch wenn die Character- und die String-Klasse arm an weiteren Methoden zu den Unicode-Blöcken und Unicode-Skripten sind, gibt es doch Unterstützung von ganz anderer Stelle: von den regulären Ausdrücken. Sie können testen, ob Zeichen in gewissen Skripten oder Blöcken enthalten sind, und damit Zeichen in Teil-Strings aufspüren, sie löschen und entfernen. (Wir springen nun thematisch etwas vor.) Die Syntax in den regulären Ausdrücken ist \p{script=Skriptname} bzw. \p{block=Blockname} (auch das Präfix Is oder In ist ohne Nutzung des script=/block=-Konstrukts erlaubt). Achtung, nicht alle Unicode-Skripte werden unterstützt!
[zB]Beispiel
Teste drei Zeichen darauf, ob sie arabisch sind:
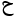 ".matches( "\\p{script=Arabic}" ) ); // true
".matches( "\\p{script=Arabic}" ) ); // trueSystem.out.println( "
".matches( "\\p{IsArabic}" ) ); // trueSystem.out.println( "
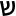 ".matches( "\\p{IsArabic}" ) ); // false
".matches( "\\p{IsArabic}" ) ); // falseSystem.out.println( "1".matches( "\\p{IsArabic}" ) ); // false
Die Abfrage testet mithilfe von regulären Ausdrücken, was Teil der nächsten Seiten ist.
 Jetzt Buch bestellen
Jetzt Buch bestellen



