
4Datenstrukturen und Algorithmen 
Ȇberlege einmal, bevor du gibst, zweimal, bevor du annimmst,
und tausendmal, bevor du verlangst.«
– Marie von Ebner-Eschenbach (1830–1916)
Algorithmen[ 40 ](Das Wort Algorithmus geht auf den Namen des persisch-arabischen Mathematikers Ibn Mûsâ Al-Chwârismî zurück, der im 9. Jahrhundert lebte.) sind ein zentrales Thema der Informatik. Ihre Erforschung und Untersuchung nimmt dort einen bedeutenden Platz ein. Algorithmen operieren nur dann effektiv mit Daten, wenn diese geeignet strukturiert sind. Schon das Beispiel Telefonbuch zeigt, wie wichtig die Ordnung der Daten nach einem Schema ist. Die Suche nach einer Telefonnummer bei gegebenem Namen gelingt schnell, während die Suche nach einem Namen bei bekannter Telefonnummer ein mühseliges Unterfangen darstellt. Datenstrukturen und Algorithmen sind also eng miteinander verbunden, und die Wahl der richtigen Datenstruktur entscheidet über effiziente Laufzeiten; beide erfüllen allein nie ihren Zweck. Leider ist die Wahl der »richtigen« Datenstruktur nicht so einfach, wie es sich anhört, und eine Reihe von schwierigen Problemen in der Informatik ist wohl deswegen noch nicht gelöst, weil eine passende Datenorganisation bis jetzt nicht gefunden wurde.
Die wichtigsten Datenstrukturen, wie Listen, Mengen, Kellerspeicher und Assoziativspeicher, sollen in diesem Kapitel vorgestellt werden. In der zweiten Hälfte des Kapitels wollen wir uns dann stärker den Algorithmen widmen, die auf diesen Datenstrukturen operieren.
4.1Datenstrukturen und die Collection-API
Dynamische Datenstrukturen passen ihre Größe der Anzahl der Daten an, die sie aufnehmen. Schon in Java 1.0 brachte die Standardbibliothek fundamentale Datenstrukturen mit, aber erst mit Java 1.2 wurde mit der so genannten Collection-API der Umgang mit Datenstrukturen und Algorithmen auf eine gute Basis gestellt. In Java 5 gab es große Anpassungen durch Einführung der Generics und in Java 8 Anpassungen durch das neue Sprachkonstrukt der Lambda-Ausdrücke. Die Datenstrukturen finden sich allesamt im Java-Paket java.util respektive Unterpaket java.util.concurrent.
Sprachregelung
Ein Container ist ein Objekt, das wiederum andere Objekte aufnimmt und die Verantwortung für die Elemente übernimmt. Wir werden die Begriffe Container, Sammlungund Collection synonym[ 41 ](Wie war noch mal das andere Wort für synonym?) verwenden.
4.1.1Designprinzip mit Schnittstellen, abstrakten und konkreten Klassen
Das Design der Collection-Klassen folgt vier Prinzipien:
Schnittstellen legen Gruppen von Operationen für die verschiedenen Behältertypen fest. So gibt es zum Beispiel mit List eine Schnittstelle für Sequenzen (Listen) und mit Map eine Schnittstelle für Assoziativspeicher, die Schlüssel-Wert-Paare verbinden.
Konkrete Klassen für bestimmte Behältertypen beerben die entsprechende abstrakte Basisklasse und ergänzen die unbedingt erforderlichen Grundoperationen (und ergänzen einige die Performance steigernde Methoden gegenüber der allgemeinen Lösung in der Oberklasse). Sie sind in der Nutzung unsere direkten Ansprechpartner. Für eine Liste können wir zum Beispiel die konkrete Klasse ArrayList und als Assoziativspeicher die Klasse TreeMap nutzen.
Algorithmen, wie die Suche nach einem Element, gehören zum Teil zur Schnittstelle der Datenstrukturen. Zusätzlich gibt es mit der Klasse Collections eine Utility-Klasse mit weiteren Algorithmen.
Weniger interessant für Anwender, aber für Implementierer einer Datenstruktur sind eine Vielzahl abstrakte Basisklassen, die die Operationen der Schnittstellen soweit wie möglich realisieren und auf eine minimale Zahl von als abstrakt deklarierten Grundoperationen zurückführen. So greift etwa addAll(…) auf mehrere add(…)-Aufrufe zurück oder isEmpty() auf getSize(). (Mit den abstrakten Basisimplementierungen wollen wir uns nicht weiter beschäftigen. Sie sind interessanter, wenn eigene Datenstrukturen auf der Basis der Grundimplementierung entworfen werden.)
4.1.2Die Basisschnittstellen Collection und Map
Alle Datenstrukturen aus der Collection-API fußen auf zwei Schnittstellen:
Durch die gemeinsame Schnittstelle erhalten alle implementierenden Klassen einen gemeinsamen Rahmen. Die Operationen lassen sich grob einteilen in:
Basisoperationen zum Erfragen der Elementanzahl und zum Hinzufügen, Löschen, Selektieren und Finden von Elementen
Mengenoperationen, um etwa andere Sammlungen einzufügen
Feldoperationen bei Collection, um die Sammlung in ein Array zu konvertieren, und bei Map in Operationen, um alternative Ansichten von Schlüsseln oder Werten zu bekommen
4.1.3Die Utility-Klassen Collections und Arrays
Datenstrukturen implementieren Algorithmen, etwa die Verwaltung von Elementen in einem Binärbaum oder einem Array. Java bietet zudem zwei besondere Klassen für insbesondere Such- und Sortier-Algorithmen: die Utility-Klasse Collections bietet Hilfsmethoden für Collection-Objekte – und einige wenige Methoden für Mengen –, und Arrays bietet statische Hilfsmethoden für Felder. Wichtig ist, auf die Schreibweise zu achten: Collection versus Collections. Die Namensgebung ist jedoch einheitlich, denn in der gesamten Java-API gibt es mehrere Beispiele für Utility-Klassen, die ein »s« am Ende bekommen und ausschließlich statische Methoden bereitstellen. Einige Algorithmen sind auch direkt bei den Klassen zu finden, so etwa sort(…) bei Listen, aber auch Collections bietet eine sort(…)-Methode.
4.1.4Das erste Programm mit Container-Klassen
Bis auf Assoziativspeicher implementieren alle Container-Klassen das Interface Collection und haben dadurch schon wichtige Methoden, um Daten aufzunehmen, zu manipulieren und auszulesen. Das folgende Programm erzeugt als Datenstruktur eine verkettete Liste, fügt Strings ein und gibt zum Schluss die Sammlung auf der Standardausgabe aus:
Listing 4.1com/tutego/insel/util/MyFirstCollection.java, MyFirstCollection
private static void fill( Collection<String> c ) {
c.add( "Juvy" );
c.add( "Tina" );
c.add( "Joy" );
}
public static void main( String[] args ) {
List<String> c = new LinkedList<>();
fill( c );
System.out.println( c ); // [Juvy, Tina, Joy]
Collections.sort( c );
System.out.println( c ); // [Joy, Juvy, Tina]
}
}
Das Beispiel zeigt unterschiedliche Aspekte der Collection-API:
Alle Datenstrukturen sind generisch deklariert. Statt new LinkedList() schreiben wir zum Beispiel new LinkedList<String>(), weil die Sammlung String-Objekte aufnehmen soll und durch die Generics typsicher wird.
Unserer eigenen statischen Methode fill(Collection<String>) ist es egal, welche konkrete Collection wir ihr geben. Statt einer LinkedList hätten wir auch eine ArrayList übergeben können, denn auch sie ist vom Typ Collection. Das Gleiche gilt für Mengen (Set-Objekte), denn alle Set-Klassen implementieren ebenfalls Collection.
Eine Liste lässt sich mit add(…) füllen. Die Methode schreibt die Schnittstelle Collection vor, und LinkedList realisiert die Operation aus der Schnittstelle.
Während Collection eine Schnittstelle ist, die von unterschiedlichen Datenstrukturen implementiert wird, ist Collections eine Utility-Klasse mit vielen Hilfsmethoden, etwa zum Sortieren mit Collections.sort(…).
[+]Tipp
Nutze immer den kleinstnötigen Typ! Wir haben das an zwei Stellen getan. Statt fill (LinkedList<String> c) deklariert das Programm fill(Collection<String> c), und statt LinkedList<String> c = new LinkedList<>() nutzt es List<String> c = new LinkedList<>(). Mit der Nutzung des Basistyps lassen sich unter softwaretechnischen Gesichtspunkten leicht die konkreten Datenstrukturen ändern, aber etwa die Methodensignatur ändert sich nicht und ist breiter aufgestellt. Es ist immer schön, wenn wir – etwa aus Gründen der Geschwindigkeit oder Speicherplatzbeschränkung – auf diese Weise leicht die Datenstruktur ändern können und der Rest des Programms unverändert bleibt. Das ist die Idee der schnittstellenorientierten Programmierung, und es ist in Java selten nötig, den konkreten Typ einer Klasse direkt anzugeben.
4.1.5Die Schnittstelle Collection und Kernkonzepte
Unterschnittstellen erweitern Collection und schreiben Verhalten vor, ob etwa der Container die Reihenfolge des Einfügens beachtet, Werte doppelt beinhalten darf oder die Werte sortiert hält; List, Set, Queue, Deque und NavigableSet sind dabei die wichtigsten.
Es folgt eine Übersicht über alle Methoden:
extends Iterable<E>
boolean add(E o)
Optional. Fügt dem Container ein Element hinzu und gibt true zurück, falls sich das Element einfügen lässt. Gibt false zurück, wenn schon ein Objekt gleichen Werts vorhanden ist und doppelte Werte nicht erlaubt sind. Diese Semantik gilt etwa bei Mengen. Erlaubt der Container das Hinzufügen grundsätzlich nicht, löst er eine UnsupportedOperationException aus.boolean addAll(Collection<? extends E> c)
Fügt alle Elemente der Collection c dem Container hinzu.void clear()
Optional. Löscht alle Elemente im Container. Wird dies vom Container nicht unterstützt, wird eine UnsupportedOperationException ausgelöst.boolean contains(Object o)
Liefert true, falls der Container ein inhaltlich gleiches Element enthält.boolean containsAll(Collection<?> c)
Liefert true, falls der Container alle Elemente der Collection c enthält.boolean isEmpty()
Liefert true, falls der Container keine Elemente enthält.Iterator<E> iterator()
Liefert ein Iterator-Objekt über alle Elemente des Containers.boolean remove(Object o)
Optional. Entfernt das angegebene Objekt aus dem Container, falls es vorhanden ist.boolean removeAll(Collection<?> c)
Optional. Entfernt alle Objekte der Collection c aus dem Container.default boolean removeIf(Predicate<? super E> filter)
Entfernt alle Elemente aus dem Container, bei denen das Prädikat erfüllt ist. Neu in Java 8. (Sollte eigentlich auch als optional gekennzeichnet sein, weil es intern auf das remove() vom Iterator zurückgreift.)boolean retainAll(Collection<?> c)
Optional. Entfernt alle Objekte, die nicht in der Collection c vorkommen.int size()
Gibt die Anzahl der Elemente im Container zurück.Object[] toArray()
Gibt ein Array mit allen Elementen des Containers zurück.<T> T[] toArray(T[] a)
Gibt ein Array mit allen Elementen des Containers zurück. Verwendet das als Argument übergebene Array als Zielcontainer, wenn es groß genug ist. Sonst wird ein Array passender Größe angelegt, dessen Laufzeittyp a entspricht.boolean equals(Object o)
Prüft, a) ob das angegebene Objekt o ein kompatibler Container ist und b) ob alle Elemente aus dem eigenen Container equals(…)-gleich den Elementen des anderen Containers sind und c) ob sie – falls vorhanden – die gleiche Ordnung haben.int hashCode()
Liefert den Hashwert des Containers. Dies ist wichtig, wenn der Container als Schlüssel in Assoziativspeichern verwendet wird. Dann darf der Inhalt aber nicht mehr geändert werden, da der Hashwert von allen Elementen des Containers abhängt.
[»]Hinweis
Der Basistyp Collection ist typisiert, genauso wie die Unterschnittstellen und implementierenden Klassen. Auffällig sind die Methoden remove(Object) und contains(Object), die gerade nicht mit dem generischen Typ E versehen sind, was zur Konsequenz hat, dass diese Methoden mit beliebigen Objekten aufgerufen werden können. Fehler schleichen sich schnell ein, wenn der Typ der eingefügten Objekte ein anderer ist als der beim Löschversuch, etwa bei HashSet<Long> set mit anschließendem set.add(1L) und remove(1).
Die Schnittstelle Collection erweitert die Schnittstelle Iterable, sodass jede Datenstruktur vom Typ Collection rechts vom Doppelpunkt eines erweiterten for stehen kann – mehr dazu gleich in Abschnitt 4.1.9, »Die Schnittstelle Iterable und das erweiterte for«.
Anzeige der Veränderungen durch boolesche Rückgaben
Der Rückgabewert einiger Methoden wie addXXX(…) oder removeXXX(…) ist ein boolean und könnte natürlich auch void sein. Doch die Collection-API signalisiert über die Rückgabe, ob eine Änderung der Datenstruktur erfolgte oder nicht. Bei Mengen liefert add(…) etwa false, wenn ein gleiches Element schon in der Menge ist; add(…) ersetzt das alte nicht durch das neue.
Optionale Methoden und UnsupportedOperationException
Einige Methoden aus der Schnittstelle Collection und Unterschnittstellen sind in der API-Dokumentation als optional notiert, weil konkrete Container oder Realisierungen die Operationen nicht realisieren wollen oder können. Da eine Schnittstellenimplementierung aber auf jeden Fall die Operation als Methode implementieren muss, lösen die Methoden eine UnsupportedOperationException aus, wenn sie die Operation nicht durchführen. Es gibt zum Beispiel Nur-Lese-Container, die Lesezugriffe zulassen, aber Veränderungen abblocken. Die Reaktion auf den Änderungsversuch zeigt folgendes Beispiel:
Listing 4.2com/tutego/insel/util/UnsupportedOperationExceptionDemo.java, main()
set.add( 1 );
Collection<Integer> c = Collections.unmodifiableCollection( set );
System.out.println( c ); // [1]
c.clear(); // Exception in thread "main" java.lang.UnsupportedOperationException
Die Optional-Anmerkungen erschrecken zunächst und lassen die Klassen bzw. Schnittstellen irgendwie unzuverlässig oder nutzlos erscheinen. Die konkreten Standardimplementierungen der Collection-API bieten diese Operationen jedoch vollständig an.
Das Konzept der optionalen Operationen ist umstritten, wenn Methoden zur Laufzeit eine Exception auslösen. Besser wären natürlich kleinere separate Schnittstellen, die nur die Leseoperationen enthalten und zur Übersetzungszeit überprüft werden können; dann gäbe es jedoch deutlich mehr Schnittstellen im java.util-Paket.
Vergleiche im Allgemeinen auf Basis von equals(…)
Der Methode equals(…) kommt bei den Elementen, die in die Datenstrukturen wandern, eine besondere Rolle zu. Jedes Objekt, das eine ArrayList, LinkedList, HashSet und alle anderen Datenstrukturen[ 42 ](Lassen wir die besondere Klasse IdentityHashMap außen vor.) aufnehmen soll, muss zwingend equals(…) implementieren. Denn Methoden wie contains(…), remove(…) vergleichen die Elemente mit equals(…) auf Gleichheit und nicht mit == auf Identität.
[zB]Beispiel
Ein neues Punkt-Objekt kommt in die Datenstruktur. Nun wird es mit einem anderen equals(…)-gleichen Objekt auf das Vorkommen in der Collection geprüft und gelöscht:
list.add( new Point(47, 11) );
System.out.println( list.size() ); // 1
System.out.println( list.contains( new Point(47, 11) ) ); // true
list.remove( new Point(47, 11) );
System.out.println( list.size() ); // 0
Eigene Klassen müssen folglich equals(…) aus der absoluten Oberklasse Object überschreiben. Umgekehrt heißt das auch, dass Objekte, die kein sinnvolles equals(…) besitzen, nicht von den Datenstrukturen aufgenommen werden können; ein Beispiel hierfür ist StringBuilder/StringBuffer.
Besonderheit
Die Datenstrukturen selbst deklarieren eine equals(…)-Methode. Zwei Datenstrukturen sind equals(…)-gleich, wenn sie die gleichen Elemente – gleich nach der equals(…)-Relation – besitzen und die gleiche Ordnung haben. Ein Detail in der Implementierung überrascht jedoch. Exemplarisch:
ArrayList<String> l2 = new ArrayList<>( Arrays.asList( "" ) );
System.out.println( l1.equals( l2 ) ); // true
Die beiden Datenstrukturen sind gleich, obwohl ihre Typen unterschiedlich sind. Das ist einmalig in der Java-API. Dahinter steht, dass die equals(…)-Implementierung von etwa ArrayList, LinkedList nur betrachtet, ob das an equals(…) übergebene Objekt vom Typ List ist. Das Gleiche gilt im Übrigen auch für Set und Map. Nach dem Typtest folgen die Tests auf die Gleichheit der Elemente.
4.1.6Schnittstellen, die Collection erweitern, und Map
Es gibt einige elementare Schnittstellen, die einen Container weiter untergliedern, etwa in der Art, wie Elemente gespeichert werden.
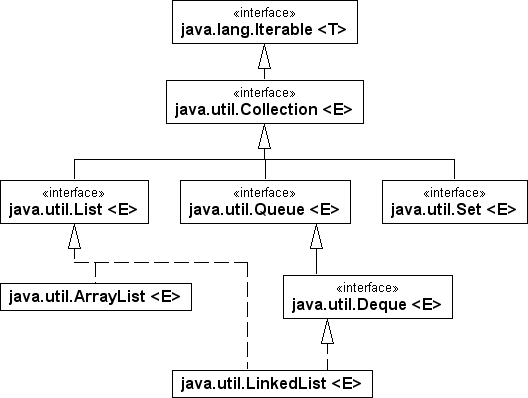
Abbildung 4.1Zentrale Schnittstellen und Klassen der Collection-API
Die Schnittstelle List für Sequenzen
Die Schnittstelle List[ 43 ](Wie in der Collection-Design-FAQ unter http://docs.oracle.com/javase/8/docs/technotes/guides/collections/designfaq.html#a11 nachzulesen ist, hätte die Schnittstelle durchaus Sequence heißen können.), die die Collection-Schnittstelle erweitert, enthält zusätzliche Operationen für eine geordnete Liste (auch Sequenz genannt) von Elementen. Auf die Elemente einer Liste lässt sich über einen ganzzahligen Index zugreifen, und es kann linear nach Elementen gesucht werden. Doppelte Elemente sind erlaubt, auch beliebig viele null-Einträge.
Zwei bekannte implementierende Klassen sind LinkedList sowie ArrayList. Weil das AWT-Paket eine Klasse mit dem Namen List deklariert, muss bei der import-Deklaration darauf geachtet werden, das richtige java.util.List statt java.awt.List zu verwenden.
Die Schnittstelle Set für Mengen
Ein Set ist eine im mathematischen Sinne definierte Menge von Objekten. Wie von mathematischen Mengen bekannt, darf ein Set keine doppelten Elemente enthalten. Für zwei nicht identische Elemente e1 und e2 eines Set-Objekts liefert der Vergleich e1.equals(e2) also immer false. Genauer gesagt: Aus e1.equals(e2) folgt, dass e1 und e2 identische Objektreferenzen sind, sich also auf dasselbe Mengenelement beziehen.
Besondere Beachtung muss Objekten geschenkt werden, die ihren Wert nachträglich ändern, da so zunächst ungleiche Mengenelemente inhaltlich gleich werden können. Dies kann ein Set nicht kontrollieren. Als weitere Einschränkung gilt, dass eine Menge sich selbst nicht als Element enthalten darf. Die wichtigste konkrete Mengen-Klasse ist HashSet.
NavigableSet – bzw. ihr Muttertyp SortedSet – erweitert Set um die Eigenschaft, Elemente sortiert auslesen zu können. Das Sortierkriterium wird durch ein Exemplar der Hilfsklasse Comparator bestimmt, oder die Elemente implementieren Comparable. Die Klassen TreeSet und ConcurrentSkipListSet implementieren die Schnittstellen und erlauben mit einem Iterator oder einer Feld-Repräsentation Zugriff auf die sortierten Elemente.
Die Schnittstelle Queue für (Warte-)Schlangen
Eine Queue arbeitet nach dem FIFO-Prinzip (für engl. first in, first out); zuerst eingefügte Elemente werden zuerst wieder ausgegeben, getreu dem Motto: »Wer zuerst kommt, mahlt zuerst.« Die Schnittstelle Queue deklariert Operationen für alle Warteschlangen und wird etwa von den Klassen LinkedList und PriorityQueue implementiert.
Queue mit zwei Enden
Während die Queue Operationen bietet, um an einem Ende Daten anzuhängen und zu erfragen, bietet die Datenstruktur Deque (vom Englischen Double-Ended QUEue) Operationen an beiden Enden. Die Klasse LinkedList ist zum Beispiel eine Implementierung von Deque. Die Datenstruktur wird wie »Deck« ausgesprochen.
Die Schnittstelle Map
Eine Datenstruktur, die einen Schlüssel (engl. key) mit einem Wert (engl. value) verbindet, heißt assoziativer Speicher. Sie erinnert an ein Gedächtnis und ist mit einem Wörterbuch oder Nachschlagewerk vergleichbar. Betrachten wir ein Beispiel: Auf einem Personalausweis findet sich eine eindeutige Nummer, eine ID, die einmalig für jeden Bundesbürger ist. Wenn nun in einem Assoziativspeicher alle Passnummern gespeichert sind, lässt sich leicht über die Passnummer (Schlüssel) die Person (Wert) herausfinden, also der Name der Person, die Gültigkeit des Ausweises usw. In die gleiche Richtung geht ein Beispiel, das ISB-Nummern mit Büchern verbindet. Ein Assoziativspeicher könnte zu der ISB-Nummer zum Beispiel das Erscheinungsjahr assoziieren, ein anderer Assoziativspeicher eine Liste von Rezensionen.
[»]Hinweis
Gerne wird als Beispiel für einen Assoziativspeicher ein Telefonbuch mit einer Assoziation zwischen Namen und Telefonnummern genannt. Wenn das mit einem Assoziativspeicher realisiert werden muss, reicht natürlich der Name alleine nicht aus, sondern der Ort/das Land müssen dazukommen (ich bin zum Beispiel nicht der einzige Christian Ullenboom; in Erlangen wohnt mein Namensvetter). Auch ist es weniger ein Problem, dass in einem Familienhaushalt mehrere Personen die gleiche Telefonnummer besitzen. Vielmehr wird die Tatsache zum Problem, dass eine Person unterschiedliche Telefonnummern, etwa eine Mobil- und Festnetznummer, besitzen kann. Damit das Modell korrekt bleibt, muss eine Assoziation zwischen einem Namen und einer Liste von Telefonnummern bestehen. Ein Assoziativspeicher ist flexibel genug dafür: Der assoziierte Wert muss kein einfacher Wert wie eine Zahl oder String sein, sondern kann eine komplexe Datenstruktur sein.
In Java schreibt die Schnittstelle Map Verhalten für einen Assoziativspeicher vor. Map ist ein wenig anders als die anderen Schnittstellen. So erweitert die Schnittstelle Map die Schnittstelle Collection nicht. Das liegt daran, dass bei einem Assoziativspeicher Schlüssel und Wert immer zusammen vorkommen müssen und die Datenstruktur eine Operation wie add(Object) nicht unterstützen kann. Im Gegensatz zu List gibt es bei einer Map auch keine Position.
Die Schlüssel einer Map können mithilfe eines Kriteriums sortiert werden. Ist das der Fall, implementieren diese speziellen Klassen die Schnittstelle NavigableMap (bzw. den Muttertyp SortedSet), die Map direkt erweitert. Das Sortierkriterium wird entweder über ein externes Comparator-Objekt festgelegt, oder die Elemente in der Map sind vom Typ Comparable. Damit kann ein Iterator in einer definierten Reihenfolge einen assoziativen Speicher ablaufen. Bisher implementieren TreeMap und ConcurrentSkipListMap die Schnittstelle NavigableMap.
4.1.7Konkrete Container-Klassen
Alle bisher vorgestellten Schnittstellen und Klassen dienen der Modellierung und dem Programmierer nur als Basistyp. Die Klassen in Tabelle 4.1 sind konkrete Klassen und können von uns benutzt werden.
Alle Datenstrukturen sind serialisierbar und implementieren Serializable, die Basisschnittstellen wie Set, List … machen das nicht!
Tabelle 4.1Konkrete Container-Klassen
Welche Container-Klasse nehmen?
Bei der großen Anzahl von Klassen sind Entscheidungskriterien angebracht, nach denen Entwickler Klassen auswählen können. Die folgende Aufzählung soll einige Vorschläge geben:
Ist eine Sequenz, also eine feste Ordnung, gefordert? Wenn ja, dann nimm eine Liste.
Soll es einen schnellen Zugriff über einen Index geben? Wenn ja, ist die ArrayList gegenüber der LinkedList im Vorteil.
Werden oft am Ende und Anfang Elemente eingefügt? Dann kann LinkedList punkten.
Wenn eine Reihenfolge der Elemente uninteressant ist, aber schnell entschieden werden soll, ob ein Element Teil einer Menge ist, erweist sich HashSet als interessant.
Sollen Elemente nur einmal vorkommen und immer sortiert bleiben? Dann ist TreeSet eine gute Wahl.
Wenn es eine Assoziation zwischen Schlüssel und Elementen geben muss, ist eine Map von Vorteil.
4.1.8Generische Datentypen in der Collection-API
Die Collection-API macht massiv Gebrauch von Generics. Das fällt unter anderem dadurch auf, dass die API-Dokumentation einen parametrisierten Typ erwähnt und die Collection-Schnittstelle zum Beispiel nicht add(Object e) deklariert, sondern add(E e). Generics gewährleisten bessere Typsicherheit, da nur spezielle Objekte in die Datenstruktur kommen. Mit den Generics lässt sich bei der Konstruktion einer Collection-Datenstruktur angeben, welche Typen zum Beispiel in der Datenstruktur-Liste erlaubt sind. Soll eine Spielerliste players nur Objekte vom Typ Player aufnehmen, so sieht die Deklaration so aus:
Mit dieser Schreibweise lässt die Liste nur den Typ Player beim Hinzufügen und Anfragen zu, nicht aber andere Typen, wie etwa Zeichenketten. Das ist eine schöne Sicherheit für den Programmierer.
Geschachtelte Generics
Die Schreibweise List<String> deklariert eine Liste, die Strings enthält. Um eine verkettete Liste aufzubauen, deren Elemente wiederum Listen mit Strings sind, lassen sich die Deklarationen auch zusammenführen:[ 44 ](Das erinnert mich immer unangenehm an C: ein Feld von Pointern, die auf Strukturen zeigen, die Pointer enthalten.)
4.1.9Die Schnittstelle Iterable und das erweiterte for
Das erweiterte for erwartet rechts vom Doppelpunkt den Typ java.lang.Iterable, um durch eine Sammlung laufen zu können. Praktisch ist, dass alle java.util.Collection-Klassen die Schnittstelle Iterable implementieren, denn damit kann das erweiterte for leicht über diverse Sammlungen laufen.
[zB]Beispiel
Füge Zahlen in eine sortierte Menge ein, und gib sie aus:
numbers.add( 10 ); numbers.add( 2 ); numbers.add( 5 );
for ( Integer number : numbers )
System.out.println( number ); // 2 5 10
Von der Datenstruktur übernimmt das erweiterte for den konkreten generischen Typ, hier Integer.
Ist die Sammlung nicht typisiert, wird die lokale Variable vom erweiterten for nicht den Typ bekommen können, sondern nur Object. Dann muss eine explizite Typanpassung im Inneren der Schleife vorgenommen werden.
[»]Hinweis
Ist die Datenstruktur null, so führt das zu einer NullPointerException:
for ( String s : list ) //
 NullPointerException zur Laufzeit
NullPointerException zur Laufzeit;
Es wäre interessant, wenn Java dann die Schleife überspringen würde, aber der Grund für die Ausnahme ist, dass die Realisierung vom erweiterten for versucht, eine Methode vom Iterable aufzurufen, was natürlich bei null schiefgeht. Bei Feldern gilt übrigens das Gleiche, auch wenn hier keine Methode aufgerufen wird.
 Jetzt Buch bestellen
Jetzt Buch bestellen



