
8.6Serielle Verarbeitung von XML mit SAX * 
Die Verarbeitung von XML-Dateien mit SAX ist vor dem Erscheinen von StAX die schnellste und speicherschonendste Methode gewesen. Der Parser liest die XML-Datei seriell und ruft für jeden Bestandteil der XML-Datei eine spezielle Methode auf. Der Nachteil ist, dass immer nur ein kleiner Bestandteil einer XML-Datei betrachtet wird und nicht die gesamte Struktur zur Verfügung steht.
8.6.1Schnittstellen von SAX
Die bei der Verarbeitung mit SAX anfallenden Ereignisse sind in verschiedenen Schnittstellen festgelegt. Die wichtigste Schnittstelle ist org.xml.sax.ContentHandler. Die Schnittstelle legt die wichtigsten Operationen für die Verarbeitung fest, denn die später realisierten Methoden ruft der Parser beim Verarbeiten der XML-Daten auf.
Die Klasse org.xml.sax.helpers.DefaultHandler ist eine leere Implementierung aller Operationen aus ContentHandler. Zusätzlich implementiert DefaultHandler die Schnittstellen DTDHandler, EntityResolver und ErrorHandler. Auf diese Schnittstellen wird hier nicht näher eingegangen.
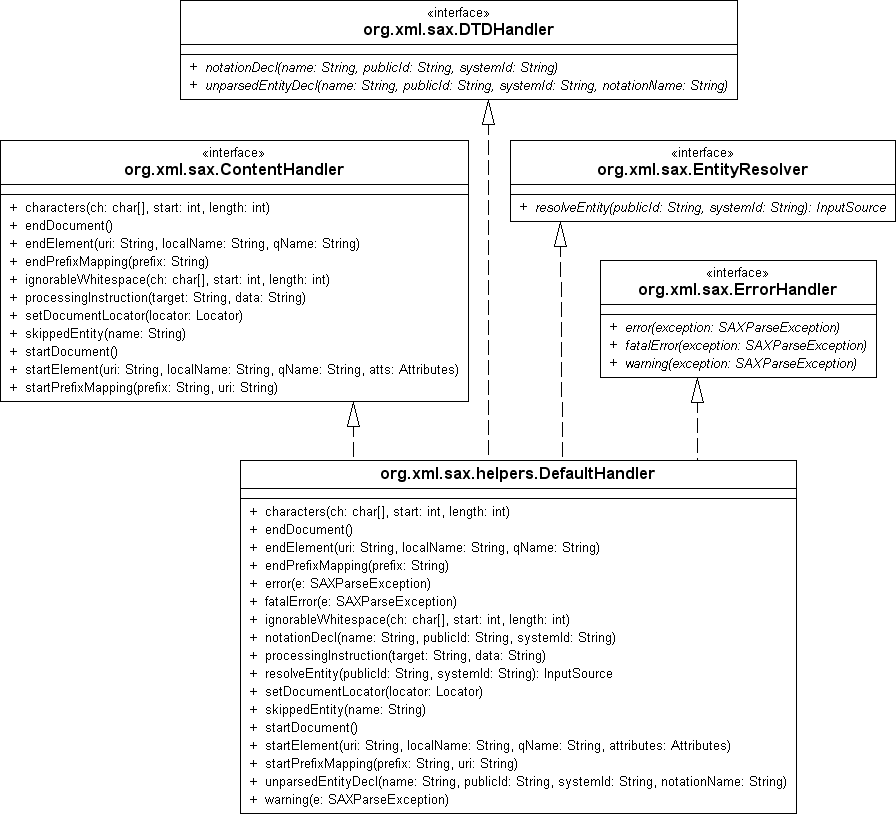
Abbildung 8.4Vererbungsbeziehung der SAX-Handler
8.6.2SAX-Parser erzeugen
Um zum Parsen einer Datei zu kommen, führt der Weg über zwei Fabrikmethoden:
Listing 8.25com/tutego/insel/xml/sax/SaxParty.java, main()
SAXParser saxParser = factory.newSAXParser();
DefaultHandler handler = new PartyHandler();
try ( InputStream in = Files.newInputStream( Paths.get( "party.xml" ) ) ) {
saxParser.parse( in, handler );
}
Mit dem SAXParser erledigt parse(…) das Einlesen. Die Methode benötigt die Datei und eine Implementierung der Callback-Methoden, die wir als PartyHandler bereitstellen.
8.6.3Operationen der Schnittstelle ContentHandler
DefaultHandler ist eine Klasse, die alle Operationen aus EntityResolver, DTDHandler, ContentHandler und ErrorHandler leer implementiert. Unsere Unterklasse PartyHandler erweitert die Klasse DefaultHandler und überschreibt interessantere Methoden, die wir mit Leben füllen wollen:
Listing 8.26com/tutego/insel/xml/sax/PartyHandler.java, Teil 1
import org.xml.sax.Attributes;
import org.xml.sax.helpers.DefaultHandler;
class PartyHandler extends DefaultHandler {
Beim Start und Ende des Dokuments ruft der Parser die Methoden startDocument() und endDocument() auf. Unsere überschriebenen Methoden geben nur eine kleine Meldung auf dem Bildschirm aus:
Listing 8.27com/tutego/insel/xml/sax/PartyHandler.java, Teil 2
public void startDocument() {
System.out.println( "Document starts." );
}
@Override
public void endDocument() {
System.out.println( "Document ends." );
}
Sobald der Parser ein Element erreicht, ruft er die Methode startElement(…) auf. Der Parser übergibt der Methode die Namensraumadresse, den lokalen Namen, den qualifizierenden Namen und Attribute:
Listing 8.28com/tutego/insel/xml/sax/PartyHandler.java, Teil 3
public void startElement( String namespaceURI, String localName,
String qName, Attributes atts ) {
System.out.println( "namespaceURI: " + namespaceURI );
System.out.println( "localName: " + localName );
System.out.println( "qName: " + qName );
for ( int i = 0; i < atts.getLength(); i++ )
System.out.printf( "Attribut no. %d: %s = %s%n", i,
atts.getQName( i ), atts.getValue( i ) );
}
Unsere Methode gibt alle notwendigen Informationen eines Elements aus. Falls kein spezieller Namensraum vergeben ist, sind die Strings namespaceURI und localName leer. Der String qName ist immer gefüllt. Die Attribute enthält der Container Attributes. Das schließende Tag eines Elements verarbeitet die Methode endElement(String namespaceURI, String localName, String qName). Bis auf die Attribute sind auch bei dem schließenden Tag alle Informationen für die Identifizierung des Elements vorhanden. Auch hier sind die Strings namespaceURI und localName leer, falls kein spezieller Namensraum verwendet wird.
Den Inhalt eines Elements verarbeitet unsere letzte Methode, characters():
Listing 8.29com/tutego/insel/sax/PartyHandler.java, Teil 4
public void characters( char[] ch, int start, int length ) {
System.out.println( "Characters:" );
for ( int i = start; i < (start + length); i++ )
System.out.printf( "%1$c (%1$x) ", (int) ch[i] );
System.out.println();
}
}
Es ist nicht festgelegt, ob der Parser den Text in einem Stück liefert oder in kleinen Stücken.[ 87 ](Die Eigenschaft nennt sich Character Chunking: http://www.tutego.de/blog/javainsel/2007/01/character-%E2%80%9Echunking%E2%80%9C-bei-sax/) Zur besseren Sichtbarkeit geben wir neben dem Zeichen selbst auch seinen Hexadezimalwert aus. So beginnt die Ausgabe mit den Zeilen:
namespaceURI:
localName:
qName: party
Attribut no. 0: datum = 31.12.2012
Characters:
(a)
(a) (20) (20) (20)
namespaceURI:
localName:
qName: gast
Attribut no. 0: name = Albert Angsthase
Characters:
(a) (20) (20) (20) (20) (20) (20)
namespaceURI:
localName:
qName: getraenk
Characters:
W (57) e (65) i (69) n (6e)
Characters:
(a) (20) (20) (20) (20) (20) (20)
namespaceURI:
localName:
qName: getraenk
Characters:
B (42) i (69) e (65) r (72)
8.6.4ErrorHandler und EntityResolver
Immer dann, wenn der Parser einen Fehler melden muss, ruft er die im ErrorHandler deklarierten Operationen auf:
void warning(SAXParseException exception)
void error(SAXParseException exception)
void fatalError(SAXParseException exception)
Da der DefaultHandler die Methoden warning(…) und error(…) leer implementiert, fällt kein Fehler wirklich auf; nur bei fatalError(…) leitet die Methode den empfangenen Fehler mit throw weiter. Das heißt aber auch, dass zum Beispiel schwache Validierungsfehler nicht auffallen. Eine Implementierung kann aber wie folgt aussehen:
throw new SAXException( saxMsg(e) );
}
private String saxMsg( SAXParseException e ) {
return "Line: " + e.getLineNumber() + ", Column: "
+ e.getColumnNumber() + ", Error: " + e.getMessage();
}
Die Klasse DefaultHandler implementiert ebenso die Schnittstelle EntityResolver, aber auch hier einfach die eine Methode InputSource resolveEntity (String publicId, String systemId) mit einem return null. Das heißt, die Standardimplementierung löst keine Entities auf. Eigene Implementierungen sehen meist im Kern so aus:
return new InputSource( new InputStreamReader( stream ) );
Die Variable dtd ist mit dem Pfadnamen einer DTD belegt, die im Klassenpfad liegen muss.
 Jetzt Buch bestellen
Jetzt Buch bestellen



