
7.6Datenströme filtern und verketten 
So wie im alltäglichen Leben Filter beim Kaffee oder bei Fotoapparaten eine große Rolle spielen, so sind sie auch bei Datenströmen zu finden. Immer dann, wenn Daten von einer Quelle gelesen oder in eine Senke geschrieben werden, können Filter die Daten auf dem Weg verändern. Die Java-Bibliothek sieht eine ganze Reihe von Filtern vor, die sich zwischen die Kommunikation schalten können:
Eingabe | Ausgabe | Anwendung |
|---|---|---|
BufferedInputStream | BufferedOutputStream | Daten puffern |
BufferedReader | BufferedWriter | |
CheckedInputStream | CheckedOutputStream | Checksumme berechnen |
DataInputStream | DataOutputStream | primitive Datentypen aus dem Strom holen und in den Strom schreiben |
DigestInputStream | DigestOutputStream | Digest (Checksumme) mitberechnen |
InflaterInputStream | DeflaterOutputStream | Kompression von Daten |
LineNumberInputStream | Mitzählen von Zeilen | |
LineNumberReader | ||
PushbackInputStream | Daten in den Lesestrom zurücklegen | |
PushbackReader | ||
CipherInputStream | CipherOutputStream | Daten verschlüsseln und entschlüsseln |
Tabelle 7.7Filter zwischen Ein- und Ausgabe
Der CipherOutputStream stammt aus dem Paket javax.crypto, manche Typen sind aus java.util.zip, DigestInputStream/DigestOutputStream sind aus dem Paket java.security, und alle anderen stammen aus java.io.
7.6.1Streams als Filter verketten (verschachteln)
Die Funktionalität der bisher vorgestellten Ein-/Ausgabeklassen reicht für den Alltag zwar aus, doch sind Ergänzungen gefordert, die die Fähigkeiten der Klassen erweitern; so zum Beispiel beim Puffern. Da die Programmlogik zur Pufferung mit Daten unabhängig von der Quelle ist, aus der die Daten stammen, findet sich die Pufferung in einer gesonderten Klasse. Java implementiert hier ein bekanntes Muster, das sich Dekorator nennt.
[zB]Beispiel
Das Modell für diese Verkettung ist immer gleich, am Beispiel fiktiver Writer-Klassen:
Writer w2 = new YYYWriter( w1 );
Writer w3 = new ZZZWriter( w2 );
Oder anders geschrieben:
Da wir das Schließen nicht vergessen dürfen, setzen wir in der Regel die Kette in einen try-mit-Ressourcen-Block:
Writer w2 = new YYYWriter( w1 );
Writer w3 = new ZZZWriter( w2 ) ) { … }
Der try-Block schließt w3 zuerst, dann w2 und w1. Dass in der Regel ein w3.close() ein w2.close() involviert, und w2 dann noch einmal vom try mit Ressourcen geschlossen wird, ist in der Regel in Ordnung, da mehrfaches Schließen nicht falsch ist. Es gibt aber Ressourcen, die nur einmal geschlossen werden können, weil sie sonst Ausnahmen werden – diese lassen sich dann verkettet nicht mit try mit Ressourcen verwalten.
Schauen wir uns die Klassen im Paket java.io genau an, die andere Ströme im Konstruktor entgegennehmen:
BufferedWriter, PrintWriter, FilterWriter nehmen Writer.
BufferedReader, FilterReader, LineNumberReader, PushbackReader, StreamTokenizer nehmen Reader.
BufferedOutputStream, DataOutputStream, FilterOutputStream, ObjectOutputStream,
OutputStreamWriter, PrintStream, PrintWriter nehmen OutputStream.BufferedInputStream, DataInputStream, FilterInputStream, InputStreamReader,
ObjectInputStream, PushbackInputStream nehmen InputStream.
Beispiel zum BufferedInputStream mit Datei-Reader und einigen anderen Klassen
Mit Files.newInputStream(…) bekommen wir einen InputStream, der aus Dateien list. Wir wollen jedoch Zugriffe immer puffern, denn Dateizugriffe sind sonst etwas langsam. Anstatt also Byte für Byte aus der Datei zu lesen, soll erst einmal ein Bündel von Daten in einen Puffer gelesen werden und Lesezugriffe dann aus diesem Puffer heraus erfolgen. Der Konstruktor von BufferedInputStream nimmt jeden beliebigen InputStream entgegen, denn der Pufferung ist es egal, ob die Daten aus einer Datei, Datenbank oder vom Netzwerk gelesen werden. Das Prinzip ist also immer, dass der Filter einen anderen Strom annimmt, an den er die Daten weitergibt oder von dem er sie holt. In unserem Fall: Der BufferedInputStream wird also beim ersten Lesen an die Datei gehen und sich den Puffer vollmachen. Jeder Lesezugriff vom Programm geht an den BufferedInputStream und nicht an den Stream von der Datei. Beim BufferedInputStream wollen wir aber nicht aufhören. Wir ummanteln diesen InputStream mit einem DigestInputStream, um beim Einlesen eine Checksumme berechnen zu können; damit lässt sich feststellen, ob die Datei verändert wurde. Danach übergeben wir den DigestInputStream an einen InputStreamReader, der den Byte-Strom in einen Zeichenstrom konvertiert. Diesen Reader übergeben wir Scanner, damit wir zeilenweise die Datei ausgeben können:
Listing 7.16com/tutego/insel/io/writer/ChainedReader.java, main()
InputStream bis = new BufferedInputStream( fis );
DigestInputStream dis = new DigestInputStream( bis,
MessageDigest.getInstance( "SHA-256" ) );
Reader isr = new InputStreamReader( dis, StandardCharsets.ISO_8859_1 );
Scanner scanner = new Scanner( isr ) ) {
while ( scanner.hasNextLine() )
System.out.println( scanner.nextLine() );
System.out.printf( "%X", new BigInteger( 1, dis.getMessageDigest().digest() ) );
}
catch ( IOException e ) {
System.err.println( "Konnte Datei nicht einlesen!" );
e.printStackTrace();
}
catch ( NoSuchAlgorithmException e ) {
System.err.println( "SHA-256 ist unbekannt!" );
}
7.6.2Gepufferte Ausgaben mit BufferedWriter und BufferedOutputStream
Die Klassen BufferedWriter und BufferedOutputStream haben die Aufgabe, die mittels write(…) in den Ausgabestrom geleiteten Ausgaben zu puffern. Dies ist immer dann nützlich, wenn viele Schreiboperationen gemacht werden, denn das Puffern macht insbesondere Dateioperationen wesentlich schneller, da so mehrere Schreiboperationen zu einer zusammengefasst werden. Um die Funktionalität eines Puffers zu erhalten, besitzen die Klassen einen internen Puffer, in dem die Ausgaben von write(…) zwischengespeichert werden. Standardmäßig fasst der Puffer 8.192 Symbole. Er kann aber über einen parametrisierten Konstruktor auf einen anderen Wert gesetzt werden. Erst wenn der Puffer voll ist oder die Methoden flush() oder close() aufgerufen werden, werden die gepufferten Ausgaben geschrieben. Durch die Verringerung der Anzahl tatsächlicher write(…)-Aufrufe an das externe Gerät erhöht sich die Geschwindigkeit der Anwendung im Allgemeinen deutlich.

Abbildung 7.7BufferedWriter ist ein Writer und dekoriert einen anderen Writer.
Um einen BufferedWriter/BufferedOutputStream anzulegen, gibt es zwei Konstruktoren, denen ein bereits existierender Writer/OutputStream übergeben wird. An diesen Writer/OutputStream wird dann der Filter seinerseits die Ausgaben weiterleiten, insbesondere nach einem Aufruf von flush(), close() oder einem internen Überlauf.
extends Writer extends FilterOutputStream
BufferedWriter(Writer out)
BufferedOutputStream(OutputStream out)
Erzeugt einen puffernden Ausgabestrom mit der Puffergröße von 8.192 Symbolen.BufferedWriter(Writer out, int sz)
BufferedOutputStream(OutputStream out, int size)
Erzeugt einen puffernden Ausgabestrom mit einer Puffergröße. Ist sie nicht echt größer 0, gibt es eine IllegalArgumentException.
Alle write(…)- und append(…)-Methoden sind so implementiert, dass die Daten erst im Puffer landen. Wenn der Puffer voll ist – oder flush() aufgerufen wird –, werden sie an den im Konstruktor übergebenen Writer durchgespült.
Zusätzlich bietet die Klasse BufferedWriter die Methode newLine(), die in der Ausgabe eine neue Zeile beginnt. Das Zeichen für den Zeilenwechsel wird aus der Systemeigenschaft line.separator genommen. Da sie intern mit der write(…)-Methode arbeitet, kann sie eine IOException auslösen.
[»]Hinweis
Ein über Files bezogener Reader/Writer ist automatisch gepuffert; das drückt auch schon der Methodenname aus: Files.newBufferedReader(…) und Files.newBufferedWriter(…). Sie noch einmal zu ummanteln ist unnötig.
7.6.3Gepufferte Eingaben mit BufferedReader/BufferedInputStream
Die Klassen BufferedReader und BufferedInputStream puffern Eingaben. Die Daten werden also zuerst in einen Zwischenspeicher geladen, was insbesondere bei Dateien zu weniger Zugriffen auf den Datenträger führt und so die Geschwindigkeit der Anwendung erhöht. Neben der Eigenschaft, dass BufferedReader als Filter eingesetzt wird, bietet er noch zwei Extramethoden zum komfortablen Lesen von Eingaben.
Die Klassen BufferedReader und BufferedInputStream besitzen je zwei Konstruktoren. Bei einem lässt sich die Größe des internen Puffers angeben. Die Puffergröße beträgt wie beim BufferedWriter/BufferedOutputStream standardmäßig 8.192 Einträge.
extends Reader extends FilterInputStream
BufferedReader(Reader in)
BufferedInputStream(InputStream in)
Erzeugt einen puffernden Zeichenstrom mit der Puffergröße von 8.192.BufferedReader( Reader in, int sz )
BufferedInputStream(InputStream in, int size)
Erzeugt einen puffernden Zeichenstrom mit der gewünschten Puffergröße.
Da ein BufferedReader Markierungen und Sprünge erlaubt, werden die entsprechenden Methoden von Reader überschrieben.
[»]Hinweis
Insbesondere beim externen Hintergrundspeichern ergibt eine Pufferung Sinn. So sollten zum Beispiel die dateiorientierten Klassen immer gepuffert werden, insbesondere, wenn einzelne Bytes/Zeichen gelesen oder geschrieben werden.
Ohne Pufferung | In der Regel schneller mit Pufferung |
|---|---|
new FileInputStream(f) | new BufferedInputStream(new FileInputStream(f)) |
new FileOutputStream(f) | new BufferedOutputStream(new FileOutputStream(f)) |
Zeilen lesen mit BufferedReader und readLine()/stream()
Die Klasse BufferedReader stellt die Methode readLine() zur Verfügung, die eine komplette Textzeile liest und als String an den Aufrufer zurückgibt; BufferedOutputStream als byteorientierte Klasse bietet die Methode nicht an. Mit dieser Methode lässt sich jeder Datenstrom komplett Zeile für Zeile ablaufen. Eine weitere Methode ist neu seit Java 8: lines(). Sie liefert keinen String, sondern einen Stream von String-Objekten. Für ein Beispiel siehe auch Abschnitt 7.1.3, »Zeichenorientierte Datenströme über Files beziehen«.
extends Reader
String readLine() throws IOException
Liest eine Zeile bis zum Zeilenende und gibt den String ohne die Endezeichen zurück. Die Rückgabe ist null, wenn der Stream am Ende ist.Stream<String> lines()
Liefert einen Stream von Strings. Im Fehlerfall wird keine geprüfte Ausnahme ausgelöst, sondern eine ungeprüfte Ausnahme vom Typ UncheckedIOException. Neu in Java 8.
7.6.4LineNumberReader zählt automatisch Zeilen mit *
Aus BufferedReader geht direkt die – bisher einzige – Unterklasse LineNumberReader hervor, die Zeilennummern zugänglich macht. Sie verfügt damit natürlich auch über readLine(). Mit getLineNumber() und setLineNumber(int) lässt sich aber zusätzlich auf die Zeilennummer zugreifen. Dass die Zeilennummer auch geschrieben werden kann, ist sicherlich ungewöhnlich, intern wird aber nur die Variable lineNumber geschrieben; der Datenzeiger wird nicht verändert.
Bei jedem read(…) untersuchen die Methoden, ob im Eingabestrom ein »\n«, »\r« oder eine Folge dieser beiden Zeichen vorkommt. Wenn dies der Fall ist, inkrementieren sie die Variable lineNumber. Zeilennummern beginnen bei 0.

Abbildung 7.8Die Klassenhierarchie von LineNumberReader
extends BufferedReader
LineNumberReader(Reader in)
Dekoriert einen gegebenen Reader.LineNumberReader(Reader in, int sz)
Dekoriert einen gegebenen Reader mit gegebener Puffergröße.int getLineNumber()
Liefert die aktuelle Zeilennummer.void setLineNumber(int lineNumber)
Setzt die aktuelle Zeilennummer.
7.6.5Daten mit der Klasse PushbackReader zurücklegen *
Die Klassen PushbackReader und PushbackInputStream können schon gelesene Eingaben wieder in den Strom zurücklegen. Das ist nützlich für so genannte vorausschauende Parser, die eine Wahl anhand des nächsten gelesenen Zeichens treffen. Mit den beiden Klassen kann dieses Vorschauzeichen wieder in den Eingabestrom gelegt werden, wenn der Parser den Weg doch nicht verfolgen möchte. Der nächste Lesezugriff liest dann nämlich dieses zurückgeschriebene Zeichen.
Die Filterklassen besitzen einen internen Puffer beliebiger Größe, in dem Symbole gespeichert werden, um sie später zurückholen zu können. Im Folgenden wollen wir uns nur mit dem PushbackReader beschäftigen; die Nutzung der Klasse PushbackInputStream ist ähnlich.

Abbildung 7.9UML-Diagramm mit den PushbackXXX-Klassen
extends FilterReader
PushbackReader(Reader in)
Erzeugt einen PushbackReader aus dem Reader in mit der Puffergröße 1.PushbackReader(Reader in, int size)
Erzeugt einen PushbackReader aus dem Reader in mit der Puffergröße size.
Um ein Zeichen oder eine Zeichenfolge wieder in den Eingabestrom zu legen, wird die Methode unread(…) ausgeführt:
public void unread(int c) throws IOException
public void unread(char[] cbuf, int off, int len) throws IOException
public void unread(char[] cbuf) throws IOException
Legt ein Zeichen oder ein Feld von Zeichen zurück in den Zeichenstrom.
PushbackReader ist ein Eingabefilter und die einzige Klasse, die direkt aus FilterReader abgeleitet ist.
Zeilennummern mit einem PushbackReader entfernen
Das nächste Programm demonstriert die Möglichkeiten eines PushbackReaders. Die Implementierung wirkt möglicherweise etwas gezwungen, sie zeigt jedoch, wie unread(char) eingesetzt werden kann. Das Programm löst folgendes Problem: Wir haben eine Textdatei (im Programm einfach als String über einen StringReader zur Verfügung gestellt), in der Zeilennummern mit dem String verbunden sind:
234Zeile
Wir wollen nun die Zahlen vom Rest der Zeilen trennen. Dazu lesen wir so lange die Zahlen ein, bis ein Zeichen folgt, bei dem Character.isDigit(…) die Rückgabe false ergibt. Dann wissen wir, dass wir keine Ziffer mehr im Strom haben. Das Problem ist nun, dass zum Testen schon ein Zeichen mehr gelesen werden musste. In einem normalen Programm ohne die Option, das Zeichen zurücklegen zu können, würde das ungemütlich. Dieses Zeichen müsste dann gesondert behandelt werden, da es das erste Zeichen der neuen Eingabe ist und nicht mehr zur Zahl gehört. Doch an Stelle dieser Sonderbehandlung legen wir es einfach wieder mit unread(char) in den Datenstrom, und dann kann der nachfolgende Programmcode einfach so weitermachen, als ob nichts gewesen wäre:
Listing 7.17com/tutego/insel/io/stream/PushbackReaderDemo.java, main()
PushbackReader in = new PushbackReader( new StringReader(s) );
for ( int c; ; ) {
try {
int number = 0;
// Read until no digit
while ( Character.isDigit((char)(c = in.read())) )
number = number * 10 + Character.digit( c, 10 );
if ( c == –1 ) // Ende erreicht? Dann aufhören
break;
in.unread( c ); // Gelesenes Zeichen zurücklegen
System.out.print( number + ":" );
while ( (c = in.read()) != –1 ) {
System.out.print( (char) c );
if ( c == '\n' )
break;
}
if ( c == –1 )
break;
}
catch ( EOFException e ) {
break;
}
}
PushbackReader und das fehlende readLine()
Da PushbackReader nicht von BufferedReader abgeleitet ist und auch selbst keine Methode readLine() anbietet, müssen wir mit einer kleinen Schleife selbst Zeilen lesen. Im Bedarfsfall muss die Zeichenkombination »\r\n« gelesen werden. So wie die Methode von uns jetzt programmiert ist, ist sie auf Plattformen beschränkt, die nur ein einziges Endezeichen einfügen. Doch warum nutzen wir nicht readLine()? Wer nun auf die Idee kommt, folgende Zeilen zu schreiben, um doch in den Genuss der Methode readLine() zu kommen, ist natürlich auf dem Holzweg:
BufferedReader br = new BufferedReader ( sr );
PushbackReader in = new PushbackReader( br );
...
br.readLine(); // Achtung, br!!
Wenn wir dem PushbackReader das Zeichen wiedergeben, dann arbeitet der BufferedReader genau eine Ebene darüber und bekommt vom Zurückgeben nichts mit. Daher ist es sehr gefährlich, die Verkettung zu umgehen. Im konkreten Fall wird das unread(char) nicht durchgeführt, und das erste Zeichen nach der Zahl fehlt.
7.6.6DataOutputStream/DataInputStream *
Während der OutputStream nur einzelne Bytes bzw. Byte-Felder schreibt und der InputStream aus einer Eingabe Bytes lesen kann, erweitern die Klassen DataOutputStream und DataInputStream diese Schreib- und Lesefähigkeit um primitive Datentypen. Die Vorgaben bekommen sie aus DataOutput und DataInput, die wir schon bei RandomAccessFile sahen. Wichtige Methoden sind zum Beispiel writeChar(char), writeInt(int), writeUTF(char) oder readUnsignedByte(), readLong() und readFully(byte[]).
[»]Hinweis
Der DataInputStream implementiert DataInput und erweitert FilterInputStream, was wiederum ein InputStream ist. Bei InputStream ist für die Methode read() eine Rückgabe von –1 vermerkt, wenn kein Byte mehr gelesen werden kann. Der DataInputStream muss aber mit einer Methode wie readLong() 8 Byte aus der Eingabe lesen.
Sind zum Beispiel nur 7 Byte im Strom und das letzte Byte kann nicht gelesen werden, ist das Ergebnis eine EOFException und nicht –1 (das kann auch nicht sein, da –1 im Datenstrom stehen könnte). Eine IOException kann auch ausgelöst werden, aber nicht, wenn Daten fehlen, sondern wenn beim Lesen der einzelnen Bytes die Ausnahme aufkam.
7.6.7Basisklassen für Filter *
Als Basisklassen für existierende Filter – und insbesondere für eigene Filter – sieht die Standardbibliothek folgende Klassen vor:
Eine konkrete Filterklasse überschreibt nötige Methoden ihrer Basisklassen (also vom InputStream, OutputStream, Reader oder Writer) und ersetzt diese durch neue Methoden mit erweiterter Funktionalität. Die folgende Abbildung stellt die zentralen Filter vor.
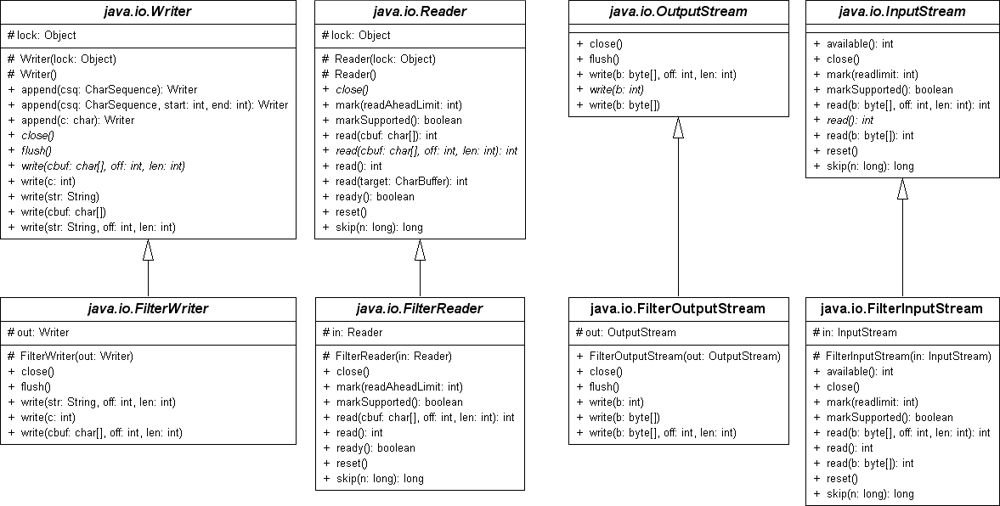
Abbildung 7.10UML-Diagramm mit ausgewählten Filterklassen
Am UML-Diagramm fällt besonders auf, dass jeder Filter zum einen selbst ein Stream ist und zum anderen einen Stream verwaltet. Damit nimmt er Daten entgegen und leitet sie gleich weiter. Das ist ein bekanntes Design-Pattern und nennt sich Dekorator.
7.6.8Die Basisklasse FilterWriter *
Die Basis für eigene zeichenorientierte Filter, die vor dem Verarbeiten vom Client modifiziert werden sollen, ist die abstrakte Klasse FilterWriter. Wir übergeben im Konstruktor ein Writer-Objekt, an das die späteren Ausgaben weitergeleitet werden. Das Konstruktor-Argument wird in dem protected-Attribut out des FilterWriter-Objekts gesichert. In der Unterklasse greifen wir darauf zurück, denn dorthin schickt der Filter seine Ausgaben.
Die Standardimplementierung der Klasse FilterWriter überschreibt drei der write(…)-Methoden so, dass die Ausgaben an den im Konstruktor übergebenen Writer gehen.
extends Writer
protected Writer out
Der Ausgabestrom, an den die Daten geschickt werden. Er wird dem Konstruktor übergeben, der ihn in out speichert.protected FilterWriter(Writer out)
Erzeugt einen neuen filternden Writer.void write(int c)
Schreibt ein einzelnes Zeichen.void write(char[] cbuf, int off, int len)
Schreibt einen Teil eines Zeichenfeldes.void write(String str, int off, int len)
Schreibt einen Teil eines Strings.void close()
Schließt den Stream.void flush()
Leert den internen Puffer des Streams.
Die Klasse ist abstrakt, also können keine direkten Objekte erzeugt werden. Dennoch gibt es einen protected-Konstruktor, der für Unterklassen wichtig ist. Abgeleitete Klassen bieten in der Regel selbst einen Konstruktor mit dem Parameter vom Typ Writer an und rufen im Rumpf mit super(write) den geschützten Konstruktor der Oberklasse FilterWriter auf. Über die initialisierte geschützte Objektvariable out kommen wir dann an diesen Ur-Writer.
7.6.9Ein LowerCaseWriter *
Wir wollen im Folgenden einen Filter schreiben, der alle in den Strom geschriebenen Zeichen in Kleinbuchstaben umwandelt. Drei Dinge sind für einen eigenen FilterWriter nötig:
Die Klasse leitet sich von FilterWriter ab.
Unser Konstruktor nimmt als Parameter ein Writer-Objekt und ruft mit super(out) den Konstruktor der Oberklasse auf, also FilterWriter. Die Oberklasse speichert das übergebene Argument in der geschützten Objektvariablen out, sodass die Unterklassen darauf zugreifen können.
Wir überlagern die drei write(…)-Methoden und eventuell noch close() und flush(). Unsere write(…)-Methoden führen dann die Filteroperationen aus und geben die wahren Daten an den Writer weiter.

Abbildung 7.11Vererbungsbeziehungen der neuen Klasse LowerCaseWriter
Listing 7.18com/tutego/insel/io/stream/LowerCaseWriterDemo.java, LowerCaseWriter
public LowerCaseWriter( Writer writer ) {
super( writer );
}
@Override
public void write( int c ) throws IOException {
out.write( Character.toLowerCase((char)c) );
}
@Override
public void write( char[] cbuf, int off, int len ) throws IOException {
write( String.valueOf( cbuf ), off, len );
}
@Override
public void write( String s, int off, int len ) throws IOException {
out.write( s.toLowerCase(), off, len );
}
}
Und die Nutzung sieht dann so aus:
Listing 7.19com/tutego/insel/io/stream/LowerCaseWriterDemo.java, LowerCaseWriterDemo main()
PrintWriter pw = new PrintWriter( new LowerCaseWriter( sw ) );
pw.println( "Eine Zeile für klein und groß" );
System.out.println( sw.toString() );
7.6.10Eingaben mit der Klasse FilterReader filtern *
Wie das Schachteln von Ausgabeströmen, so ist auch das Verbinden mehrerer Eingabeströme möglich. Als abstrakte Basiszwischenklasse existiert hier FilterReader, die ein Reader-Objekt im Konstruktor übergeben bekommt. Dieser sichert das Argument in der protected-Variablen in. (Das ist das gleiche Prinzip wie bei den anderen FilterXXX-Klassen.) Der Konstruktor ist protected, da er von der Unterklasse mit super(reader) aufgerufen werden soll. Standardmäßig leiten die Methoden vom FilterReader die Methoden an den Reader aus der Variablen in weiter; das heißt etwa: Wenn der FilterReader geschlossen wird, wird der Aufruf in.close() ausgeführt. Aus diesem Grund muss der FilterReader auch alle Methoden von Reader überschreiben, da ja eine Umleitung stattfindet.
extends Reader
protected Reader in
Der Zeicheneingabestrom oder null, wenn der Strom geschlossen wurde.protected FilterReader(Reader in)
Erzeugt einen neuen filternden Reader.
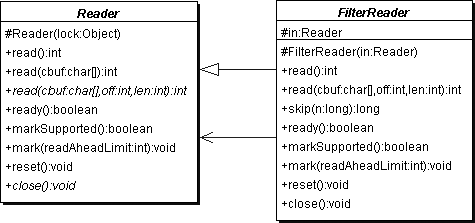
Abbildung 7.12UML-Diagramm von FilterReader
Die Methoden read(), read(char[] cbuf, int off, int len), skip(long n), ready(), markSupported(), mark(int readAheadLimit), reset() und close() werden überschrieben und leiten die Aufrufe direkt an Reader weiter. Lösen die Methoden eine Ausnahme aus, leitet der FilterReader sie standardmäßig an uns weiter.
7.6.11Anwendungen für FilterReader und FilterWriter *
Unsere nächste Klasse bringt uns etwas näher an das HTML-Format heran. Wir wollen eine Klasse HTMLWriter entwerfen, die FilterWriter erweitert und Textausgaben in HTML konvertiert. In HTML werden Tags eingeführt, die vom Browser erkannt und besonders behandelt werden. Findet etwa der Browser im HTML-Text eine Zeile der Form <strong>Dick</strong>, so stellt er den Inhalt »Dick« in fetter Schrift dar, da das <strong>-Element den Zeichensatz umstellt. Alle Tags werden in spitzen Klammern geschrieben. Daraus ergibt sich, dass HTML einige spezielle Zeichenfolgen (Entities genannt) verwendet. Wenn diese Zeichen auf der HTML-Seite dargestellt werden, muss dies durch spezielle Zeichensequenzen geschehen:
< wird zu <
> wird zu >
& wird zu &
Kommen diese Zeichen im Quelltext vor, so muss unser HTMLWriter diese Zeichen durch die entsprechende Sequenz ersetzen. Andere Zeichen sollen nicht ersetzt werden.
Den Browsern ist die Struktur der Zeilen in einer HTML-Datei egal. Sie formatieren wiederum nach speziellen Tags. Zeilenvorschübe etwa werden mit <br/> eingeleitet. Unser HTMLWriter soll zwei leere Zeilen durch das Zeilenvorschub-Element <br/> markieren.
HTML-Dokument schreiben
Alle sauberen HTML-Dateien haben einen wohldefinierten Anfang und ein wohldefiniertes Ende. Das folgende kleine HTML-Dokument ist wohlgeformt und zeigt, was unser Programm später erzeugen soll:
"http://www.w3.org/TR/html4/strict.dtd">
<html><head><title>Superkreativer Titel</title></head>
<body><p>
Und eine Menge von Sonderzeichen: < und > und &
Zweite Zeile
<br/>
Leerzeile
Keine Leerzeile danach
</p></body></html>
Der Titel der Seite sollte im Konstruktor übergeben werden können. Hier ist nun das Programm für den HTMLWriter:
Listing 7.20com/tutego/insel/io/stream/HTMLWriter.java
import java.io.*;
class HTMLWriter extends FilterWriter {
private boolean newLine;
/**
* Creates a new filtered HTML writer with a title for the web page.
*
* @param out a Writer object to provide the underlying stream.
* @throws IOException if the header cannot be written
*/
public HTMLWriter( Writer out, String title ) throws IOException {
super( out );
out.write( "<!DOCTYPE HTML PUBLIC \"-//W3C//DTD HTML 4.01//EN\"" +
" \"http://www.w3.org/TR/html4/strict.dtd\">\n" );
out.write( "<html><head><title>" + title + "</title></head>\n<body><p>\n" );
}
/**
* Creates a new filtered HTML writer with no title for the web page.
*
* @param out a Writer object to provide the underlying stream.
*/
public HTMLWriter( Writer out ) {
super( out );
}
/**
* Writes a single character.
*/
@Override
public void write( int c ) throws IOException {
switch ( c ) {
case '<':
out.write( "<" );
newLine = false;
break;
case '>':
out.write( ">" );
newLine = false;
break;
case '&':
out.write( "&" );
newLine = false;
break;
case '\n':
if ( newLine ) {
out.write( "<br/>\n" );
newLine = false;
}
else
out.write( "\n" );
newLine = true;
break;
case '\r':
break; // ignore
default :
out.write( c );
newLine = false;
}
}
/**
* Writes a portion of an array of characters.
*
* @param cbuf Buffer of characters to be written
* @param off Offset from which to start reading characters
* @param len Number of characters to be written
* @exception IOException If an I/O error occurs
*/
@Override
public void write( char[] cbuf, int off, int len ) throws IOException {
for ( int i = off; i < len; i++ )
write( cbuf[ i ] );
}
/**
* Writes a portion of a string.
*
* @param str String to be written.
* @param off Offset from which to start reading characters
* @param len Number of characters to be written
* @exception IOException If an I/O error occurs
*/
@Override
public void write( String str, int off, int len ) throws IOException {
for ( int i = off; i < len; i++ )
write( str.charAt( i ) );
}
/**
* Closes the stream.
*
* @throws IOException If the prolog can not be written or the underlying stream * not be closed
*/
@Override
public void close() throws IOException {
try {
out.write( "</p></body></html>" );
}
finally {
out.close(); // Ignoriere, falls out.close() und out.write() knallt
}
}
}
Ein Demo-Programm soll die aufbereiteten Daten in einen StringWriter schreiben:
Listing 7.21com/tutego/insel/io/stream/HTMLWriterDemo.java, main()
HTMLWriter html = new HTMLWriter( sw, "Superkreativer Titel" );
PrintWriter pw = new PrintWriter( html );
pw.println( "Und eine Menge von Sonderzeichen: < und > und &" );
pw.println( "Zweite Zeile" );
pw.println();
pw.println( "Leerzeile" );
pw.println( "Keine Leerzeile danach" );
pw.close();
System.out.println( sw.toString() );
HTML-Tags mit einem speziellen Filter überlesen
Unser nächstes Beispiel ist eine Klasse, die den FilterReader so erweitert, dass HTML-Tags überlesen werden. Die Klasse FilterReader deklariert den notwendigen Konstruktor zur Annahme des Readers, der die wirklichen Daten liefert, und überschreibt zwei read(…)-Methoden. Die read()-Methode ohne Parameter – die ein int für ein gelesenes Zeichen zurückgibt – legt einfach ein 1 Zeichen großes Feld an und ruft dann die zweite überschriebene read(char[], int , int)-Methode auf, die die Daten in ein Feld liest. Da dieser Methode neben dem Feld auch noch die Größe übergeben werden kann, müssen wirklich so viele Zeichen gelesen werden. Es reicht einfach nicht aus, die übergebene Anzahl von Zeichen vom tiefer liegenden Reader zu lesen, sondern hier müssen wir beachten, dass eingestreute Tags nicht zählen. Die Zeichenkette <p>Hallo<p> ist ja nur fünf Zeichen lang und nicht elf!
Listing 7.22com/tutego/insel/io/stream/HTMLReader.java
import java.io.*;
public class HTMLReader extends FilterReader {
private boolean inTag = false;
public HTMLReader( Reader in ) {
super( in );
}
@Override
public int read() throws IOException {
char[] buf = new char[1];
return read( buf, 0, 1 ) == –1 ? –1 : buf[0];
}
@Override
public int read( char[] cbuf, int off, int len ) throws IOException {
int numchars = 0;
while ( numchars == 0 ) {
numchars = in.read( cbuf, off, len );
if ( numchars == –1 ) // EOF?
return –1;
int last = off;
for ( int i = off; i < off + numchars; i++ ) {
if ( ! inTag ) {
if ( cbuf[i] == '<' )
inTag = true;
else
cbuf[last++] = cbuf[i];
}
else if ( cbuf[i] == '>' )
inTag = false;
}
numchars = last – off;
}
return numchars;
}
}
Ein Beispielprogramm soll die Daten aus einem StringReader ziehen. Der HTMLReader bekommt diesen StringReader und wird selbst von Scanner genutzt, damit wir die komfortable nextLine()-Methode nutzen können. Da hier keine externen Ressourcen vorkommen, müssen wir nichts schließen, und ein try mit Ressourcen kann entfallen.
Listing 7.23com/tutego/insel/io/stream/HTMLReaderDemo.java, main()
+ "Ah, wieder normal.</html>";
Reader sr = new StringReader( s );
Reader hr = new HTMLReader( sr );
Scanner scanner = new Scanner( hr );
while ( scanner.hasNextLine() )
System.out.println( scanner.nextLine() );
Es produziert dann die einfache Ausgabe:
 Jetzt Buch bestellen
Jetzt Buch bestellen



